【DX時代の研究開発とは】 R&Dの効率化・コスト削減:データ活用への取り組み
社会や顧客ニーズが急激に変化する中、多くの企業で競争力強化が求められています。化学業界では、素材開発力の強化に向けて、「マテリアルズ・インフォマティクス(MI)」の導入が近年注目され、広がりつつあります。デジタル化の技術革新により、過去の実験や論文の解析を通じ、素材の分子構造や製造方法を予測するといった素材開発の高効率化を実現しました。一方で、どのように「MI」を取り入れていけばよいのか悩んでいる化学企業様も多いのではないでしょうか?本コラムでは前編・後編とでMIへの活用ステップと成功事例をご紹介して参ります。

|
エルゼビア・ジャパン株式会社
エルゼビアは、研究機関や専門家による医療、オープンサイエンスの発展や支援を行うグローバル情報分析企業です。その中でR&Dの発展に貢献できるようSolutionを開発し、データ活用法や研究開発の課題・必要な情報に対し、ニーズに合わせたサポートやサービスも提供しています。データ駆動型の研究開発促進に寄与すべく活動を行い、様々な課題やご相談に応じています。
|
はじめに:マテリアルズ・インフォマティクスの活用ステップ
R&Dの加速、コスト削減、効率化などは多くの企業が取り組む課題であり、そのひとつがデータの活用です。材料開発のコストを削減し効率をあげる手法として、マテリアルズ・インフォマティクス(MI)を活用する企業は年々増えており、情報源となるデータにも注目が集まっています。
MIの情報源となるデータにはいくつかの種類があり、主なものは自社データ、公共データ、そして商用データです。R&Dに取り組む企業には貴重な資産として自社データが多く蓄積されていることは言うまでもありません。しかしながら、すべての企業においてこれらの自社データが有効活用されているかというと、そうとも限らないというのが現実です。データ活用のレベルはまちまちで、その中にはデータが紙(実験ノート)で存在する場合や、電子化はされているけれども研究者それぞれのPCに蓄積されているなど、これからデータ活用に向けて準備が必要な段階にあるケースがあります。その一方で、きちんと電子実験ノートでデータ管理をしている企業や、もう一段階進んで多様な種類のデータがデータレイクとして蓄積されているケース、すでにデータの統合や構造化などが行われガバナンスがされている状態で、MIへの活用準備ができているケースなどもあり、企業により状況はかなり異なります。ここでは実際にデータを活用できる状態にするためにどんなステップが必要かについて触れていきます。
データを例えばMIへ活用できる状態にするためには、いくつかのステップが必要です。そのステップには例えば下記のようなものがあります。
① 必要なデータの検討
② データ活用基盤の構築
③ データの収集・集約
④ データのクリーニング・正規化・統合
必要なデータの検討
まず行わなければならないことは必要なデータが何かを検討することです。利用できるデータの中には自社データのようにすでに手元にあるものの他に、公共データや商用のデータなどがあります。どこまでのデータが必要かは、どれだけのデータが手持ちであるかに加え、どの程度の量のデータがMIなどのデータ活用をする上で必要かを加味して決定する必要があります。もし手元にすでにあるデータだけでデータが足りないのだとすれば、公共データや商用データも検討対象とする必要があります。商用データとしては例えばエルゼビアでは、低分子化合物の物性・特性や反応情報を論文や特許から抽出して収録したデータベースReaxys(リアクシス)を提供しています(図1・図2)。Reaxys内のデータはオリジナルの情報源(論文や特許)から抽出され、構造化された状態にあり容易に利用することができます。APIによるデータの2次利用の権限(有償)も提供しており、MIを実施する企業でも活用をしていただいています。
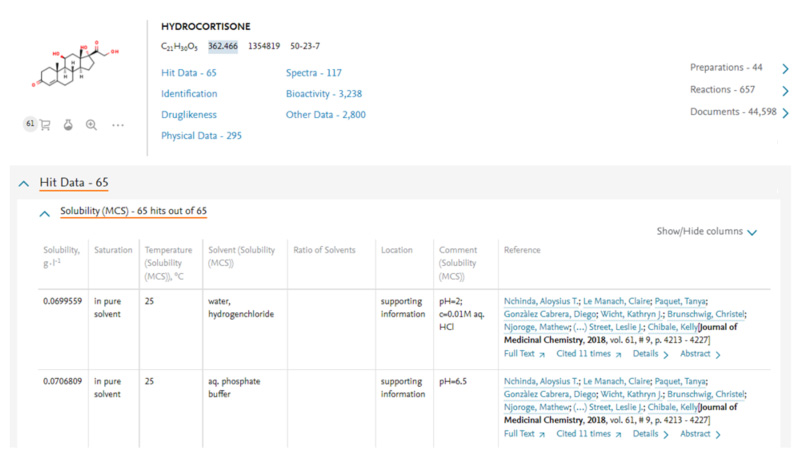
図1:ReaxysのSolubilityデータ
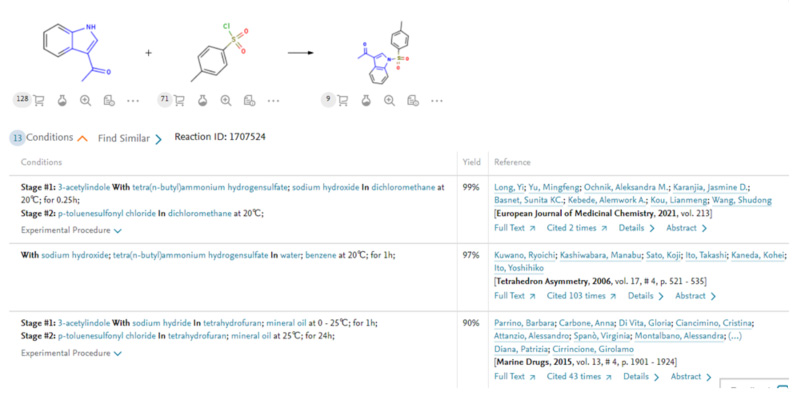
図2:Reaxys 反応情報
なお公共データも含め、MIなどへデータの利用をする場合には、MIに利用することが可能かどうかの権利関係をチェックすることも必要であることに注意しなければなりません。
データ活用基盤の構築
必要なデータが決まったら、それらを集約するデータ活用の基盤構築も重要です。データが選定されても、研究者各々のPC上にデータが存在しているようないわゆる「サイロ化」の状態ではデータは効率的に活用できません。これは多くの企業が抱えている課題でもあります。こういったサイロ化の課題を解決するためにも、データ活用基盤の構築は検討をする価値があり、今後の道筋を見据えた検討が必要です。ここでひとつ触れておきたいのは、こういったプロジェクトを実施する上で忘れてはいけないのが関係者間の合意であるという点です。特にMIのように複数の立場の人間が関係するケース、例えばデータサイエンティストと現場の研究者、それを管理する立場の管理者など関係者が多岐にわたるケースでは、最終目標とそこへの道筋について合意がなされていないと、なかなかプロジェクトとしてはうまくいかないということは念頭においておく必要があります。
データの収集・集約
関係者間の合意がなされたら、データは活用できるように収集・集約をしなければなりません。いわゆるデータレイク(多種類のデータを1か所に集約するデータレポジトリー)の構築が代表例です。すでにアクセスのある自社データなどはこういったデータレイクに集約することでその後のプロセスを効率化することができます。もしアクセスのない商用データなどが必要だとすれば、そういったデータの入手も検討が必要です。ただし一度にすべてのデータを集めることはできない可能性もあり、マイルストーンを設定して少しずつ進めていくことも失敗のリスクを回避する上では有効です。
データのクリーニング・正規化・統合
活用したいデータが集まったら、次のステップは実際にデータを活用できる状態にすることです。具体的にはデータのクリーニング、正規化、統合といったステップになります。エルゼビアでは実際にデータをハンドリングしているデータサイエンティストの方々とお話をさせていただく機会が多々ありますが、MIのモデルを構築することよりもデータのクリーニング(不要なデータや重複の削除や最新情報へのアップデートなど)にかかる手間や労力の方が多いという声が最も多く聞かれます。これは化学業界に限らず、製薬業界など他のAIを含むデータ活用を進めている業界でも同じような状況です。特に自社の情報ではこういったことが自動化されているケースはあまり多くはないため、手作業でやっているケースも多いように見受けられます。またクリーニングしたデータを正規化することもデータ活用をする上では避けて通れないステップです。例えば化合物を表現する方法ひとつとっても、構造式、IUPAC名、CAS番号、SMILES、一般名など多様な表記方法があります。これらを同一化合物として認識させるためには、データの正規化や情報を整理するための「辞書」が必要不可欠です(図3)。

図3:構造・一般名・CAS番号などが化合物に紐づく
データの正規化という点では、コストはかかるものの商用データを利用するメリットもあります。商用データの多くは複数の情報源、例えば論文と特許などから抽出した情報を、正規化された状態で収録していることが多いため、すでに構造化されてMIに利用しやすい状態になっているデータを入手できるというメリットがあります(図4・図5)。
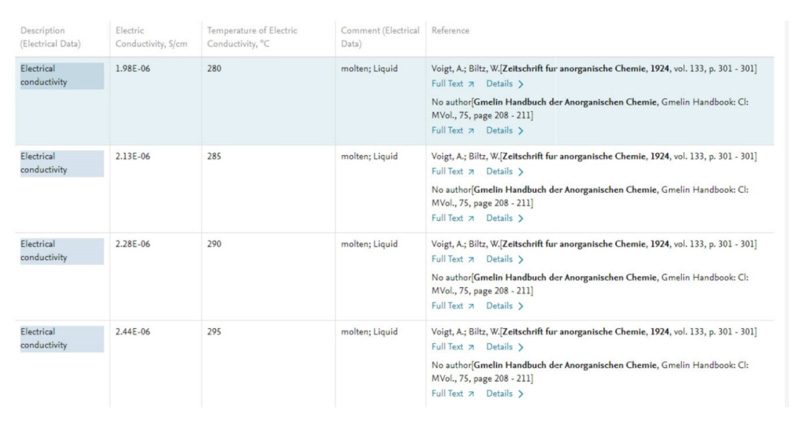
図4:Reaxys Electrical Conductivityデータ
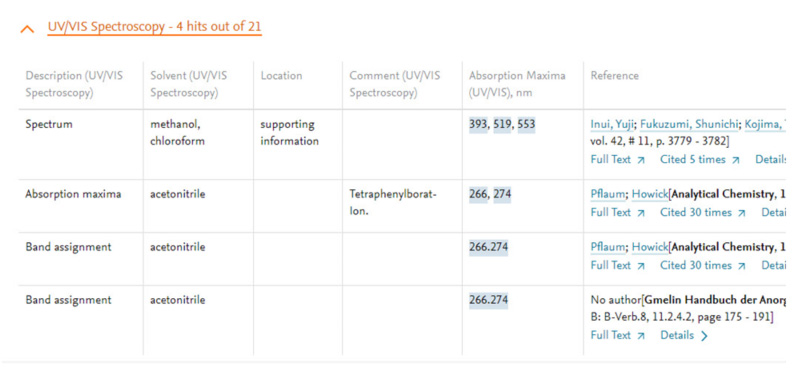
図5:Reaxys UV/VIS Spectroscopyデータ
このようなすべての作業を自社で実施することももちろん可能ですが、こういったことを専門とする外部サービスを利用することも選択肢のひとつとして検討する価値はあります。現在多くの企業で積極的にMIやAIなどへのデータ活用を進めており、成果を出している企業が多くあり、それらの成功事例は参考にする価値があります。次回の後編では実際にエルゼビアが関わっているプロジェクトの成功事例を紹介します。
後編:DXにおけるグローバルでのデータ活用推進もご覧ください。
※化学品業関連コンテンツ:化学品業向け専用ソリューションサイトもご覧ください。
化学品製造業・卸売業のビジネス課題解決のヒントに!

